Understanding LLM Context Length: What It Really Means and Why It Matters?

If you’ve ever used ChatGPT or Claude, you’ve probably hit the “context length exceeded” error at some point. Or heard companies talking about “X context window” whenever there is a new model launched. But what does this actually mean? And more importantly, why can’t you just feed a >X token document to a model trained on X context?
Let’s dig into this from both the architecture and ML systems perspective and try to understand what happens when we provide an input that exceeds the models context length and what you can do about it.
The Simple Answer
"Context length is the maximum number of tokens an LLM can process in a single forward pass. It's determined by the model's architecture and training."
- GPT-3.5: 4K tokens (~3,000 words)
- GPT-4: 8K, 32K, or 128K (depending on version)
- Claude 3: 200K tokens
- Gemini 1.5 Pro: 1M tokens
But the real question is: Why does this limit exist? And what breaks if you exceed it?
How LLMs Actually Process Text
Let me show you with actual code. Here's how a simple GPT-style model processes input:
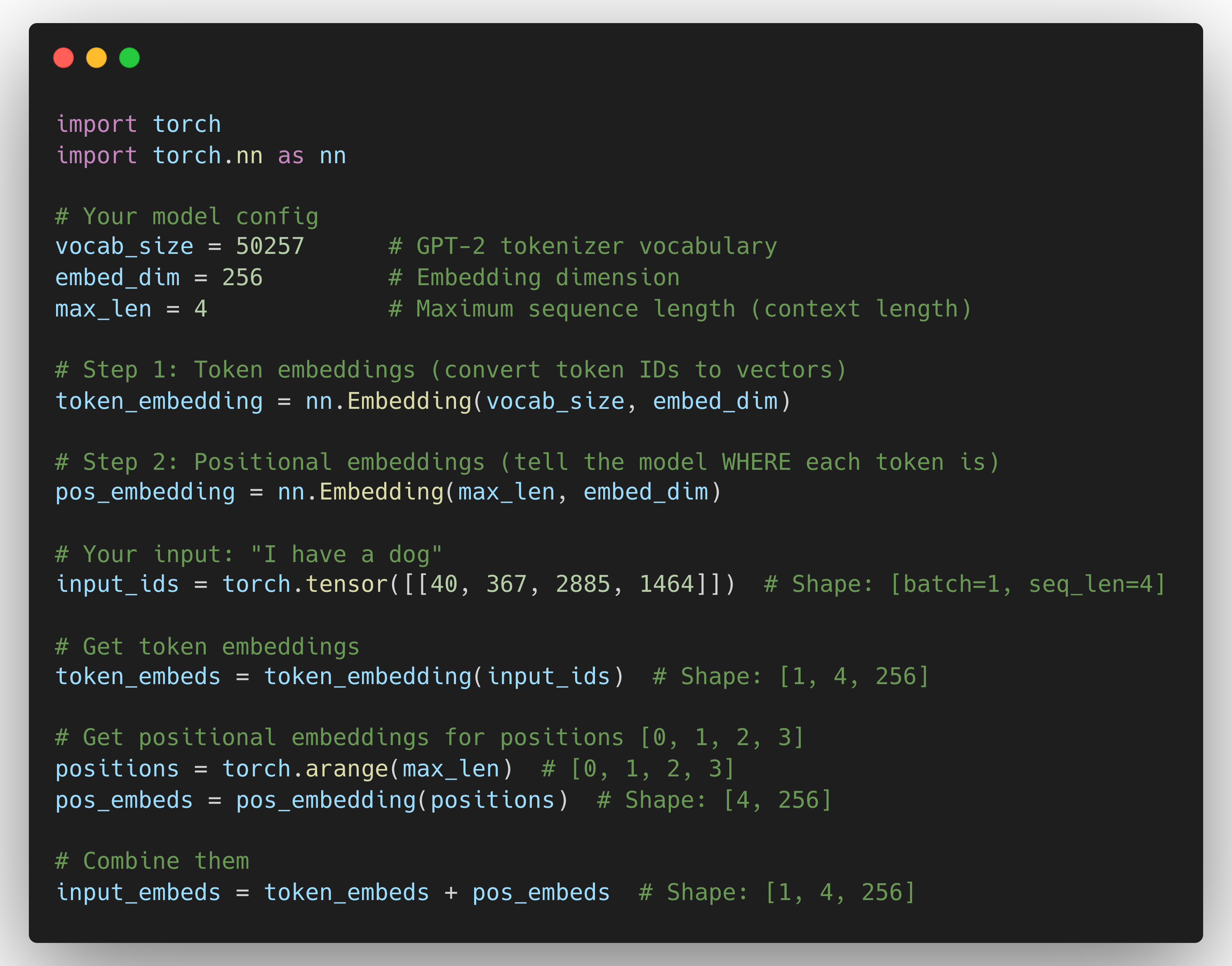
See what happened? The positional embedding layer has exactly max_len rows. One row for each position.
Now, what if you try to feed it 5 tokens?
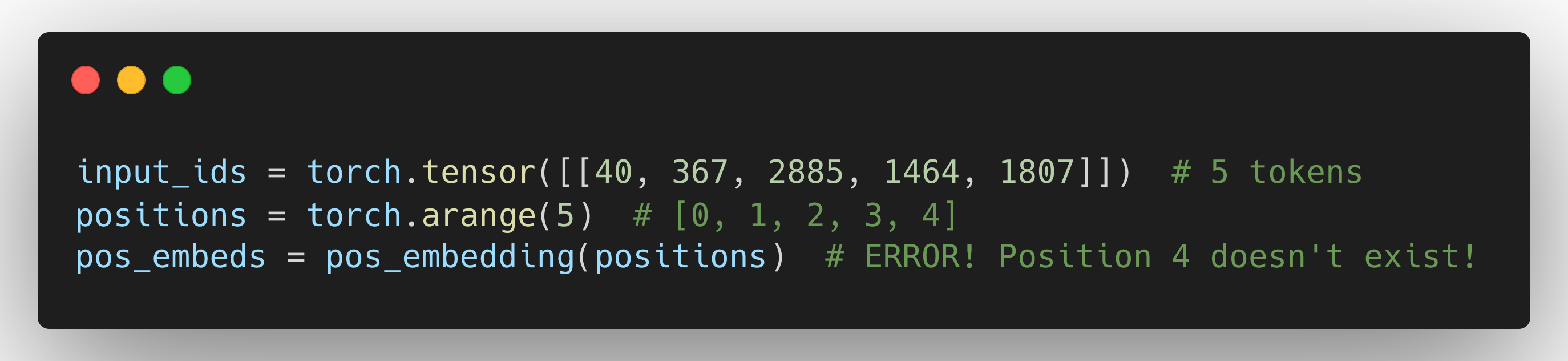
Boom. IndexError.
The model literally doesn’t have a learned embedding for position 4. You trained it on sequences of length 4, so it only knows positions [0, 1, 2, 3].
Three Hard Constraints That Define Context Length
1. Positional Embeddings (Architecture Constraint)
This is the most fundamental constraint. Your model needs to know where each token is in the sequence.
GPT-2 Style (Absolute Positional Embeddings):
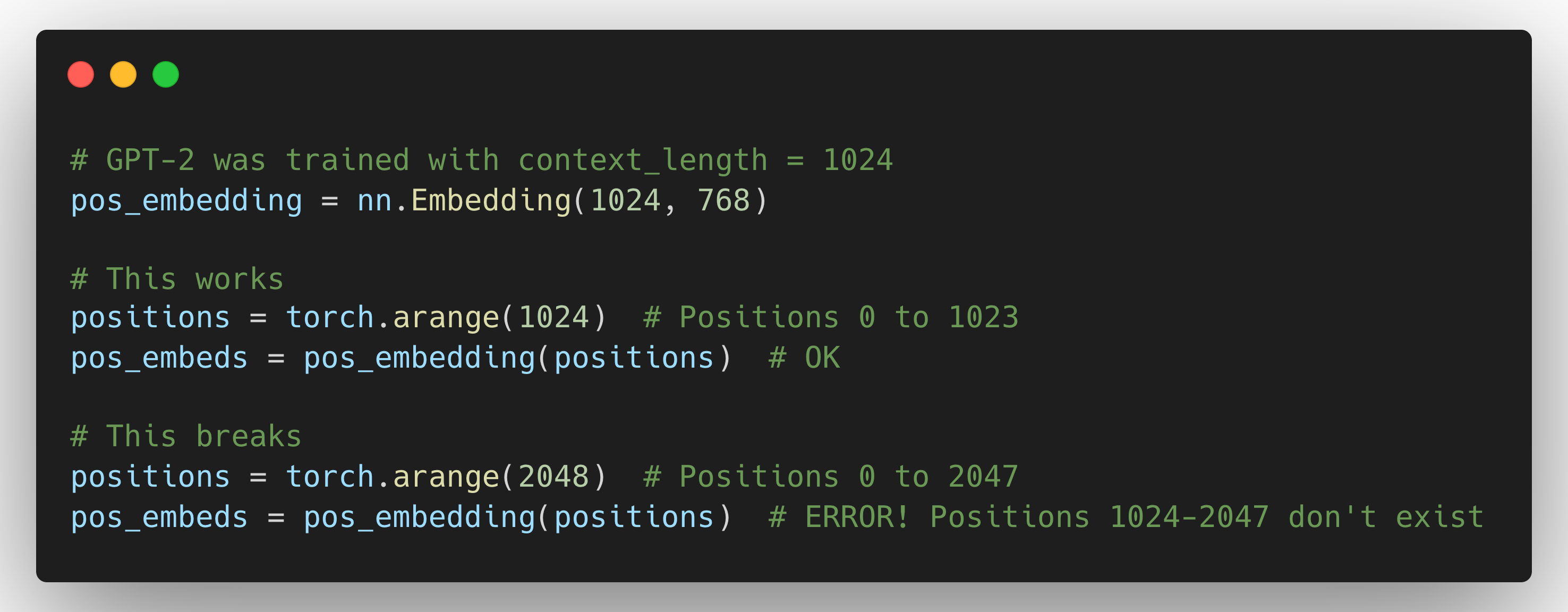
Why can't we just extend the embedding table? Because these are learned embeddings. The model learned during training that position 0 means "start of sequence", position 500 means "middle", etc. If you add rows for positions 1024-2047, they're random - the model never learned what they mean.
"Absolute embeddings fix a learned table up to a maximum length, but rotary or relative embeddings generalize better beyond trained lengths and are widely used in modern models."
2. Attention Computation (Computational Constraint)
Self-attention is O(n²) in both time and memory where n = sequence length.
For a sequence of length n, Self-attention computes an attention score for every token with every other token in the sequence, forming an n x n attention matrix.
Single attention head:
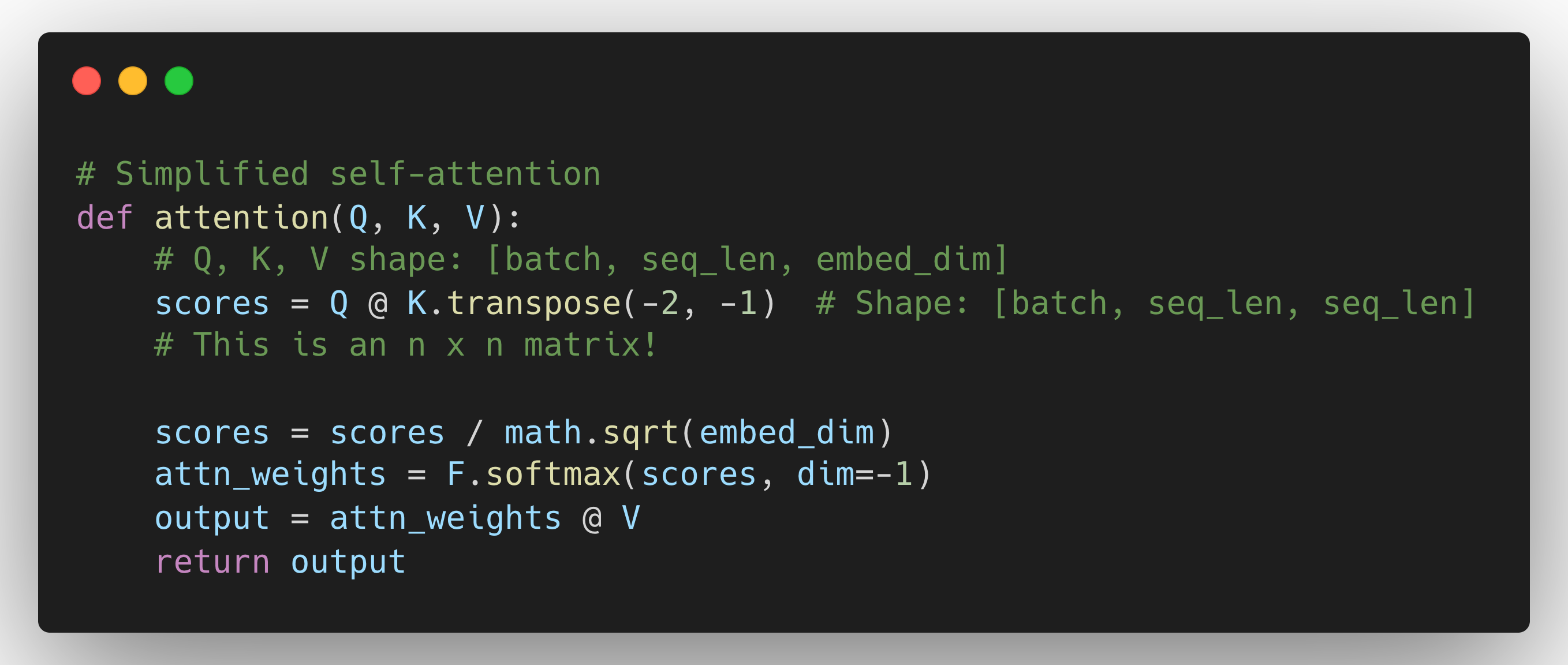
- n = 1,024: 1M elements
- n = 2,048: 4M elements (4x more)
- n = 4,096: 16M elements (16x more)
- n = 128,000: 16 BILLION elements
But here's where it gets brutal. Each transformer layer has multiple attention heads. For GPT-3 (96 layers, 96 heads):
# Memory calculation
Memory = num_layers × num_heads × n²
# At n = 128K
Total_elements = 96 × 96 × (128,000)² = 147 trillion elements
Memory_in_bytes = 147 trillion × 2 bytes (float16) = 294 TB294 TB just for attention matrices during training. This is why training long-context models from scratch requires warehouse-scale compute infrastructure.
Complexity breakdown:
- Time: O(n²) to calculate all attention scores
- Memory: O(n²) to store matrices, plus O(n²) for gradients during back-propagation
This quadratic scaling is the fundamental bottleneck for long-context LLMs.
3. KV Cache (Inference Constraint)
During inference (text generation), models use KV caching to avoid recomputing attention for previous tokens.
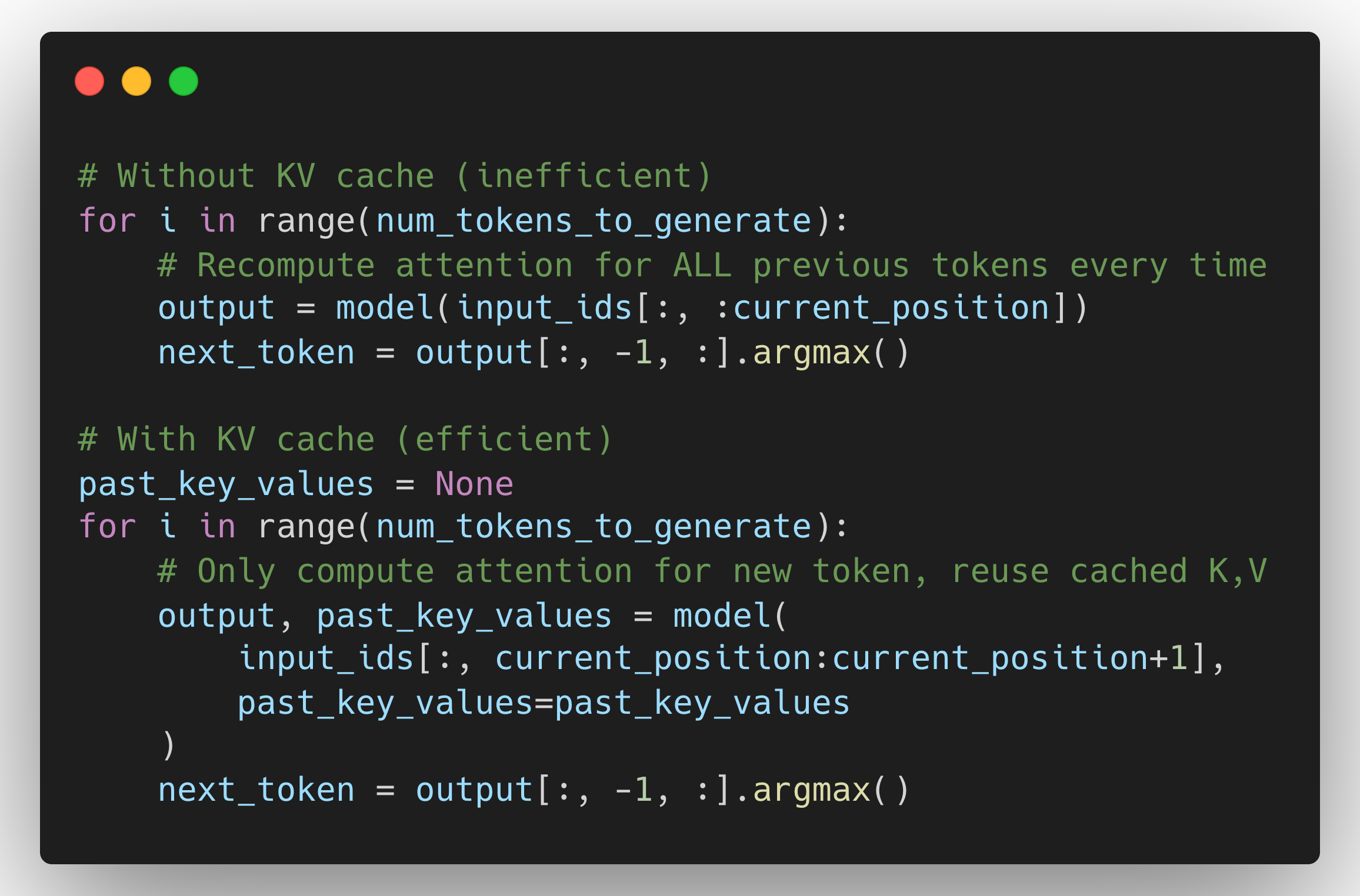
KV cache memory calculation:
KV_cache_size = 2 * num_layers * seq_len * hidden_dim * sizeof(float16)Where:
- The "2" accounts for both K and V caches
- hidden_dim = num_heads × head_dim (the total model dimension)
For GPT-3 (175B parameters) back of the envelope calculation:
- num_layers = 96
- hidden_dim = 12288
- seq_len = 2048
- *KV cache = 2 96 2048 12288 2 bytes = 9.2 GB*
For seq_len = 128K → KV cache = 576 GB 🤯
And this is per request. If you’re serving 100 concurrent users, multiply by 100.
This is why longer context = way more expensive to serve.
What Happens If You Exceed Context Length?
Let's see what actually breaks:
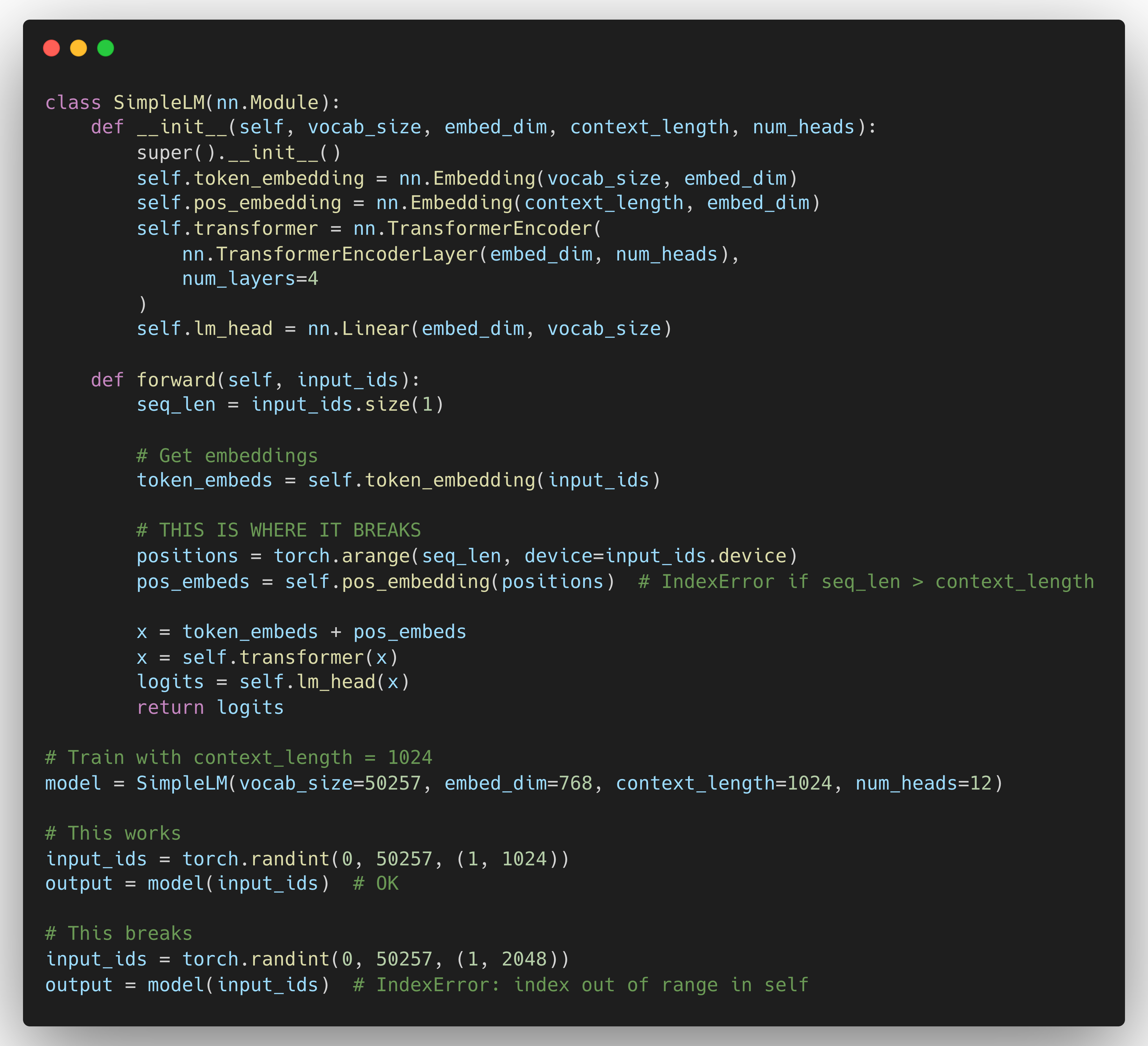
Three things break:
- Positional embeddings don't exist for positions beyond training length. Even if you bypass this limit, the performance degrades.
- Attention patterns learned during training don't generalize to longer sequences.
- Memory allocation assumes the trained context length.
Can You Extend Context Length?
Yes, but it's not trivial. Here are some techniques:
Method 1: Positional Interpolation
Instead of extending the position IDs, compress them to fit within the trained range.
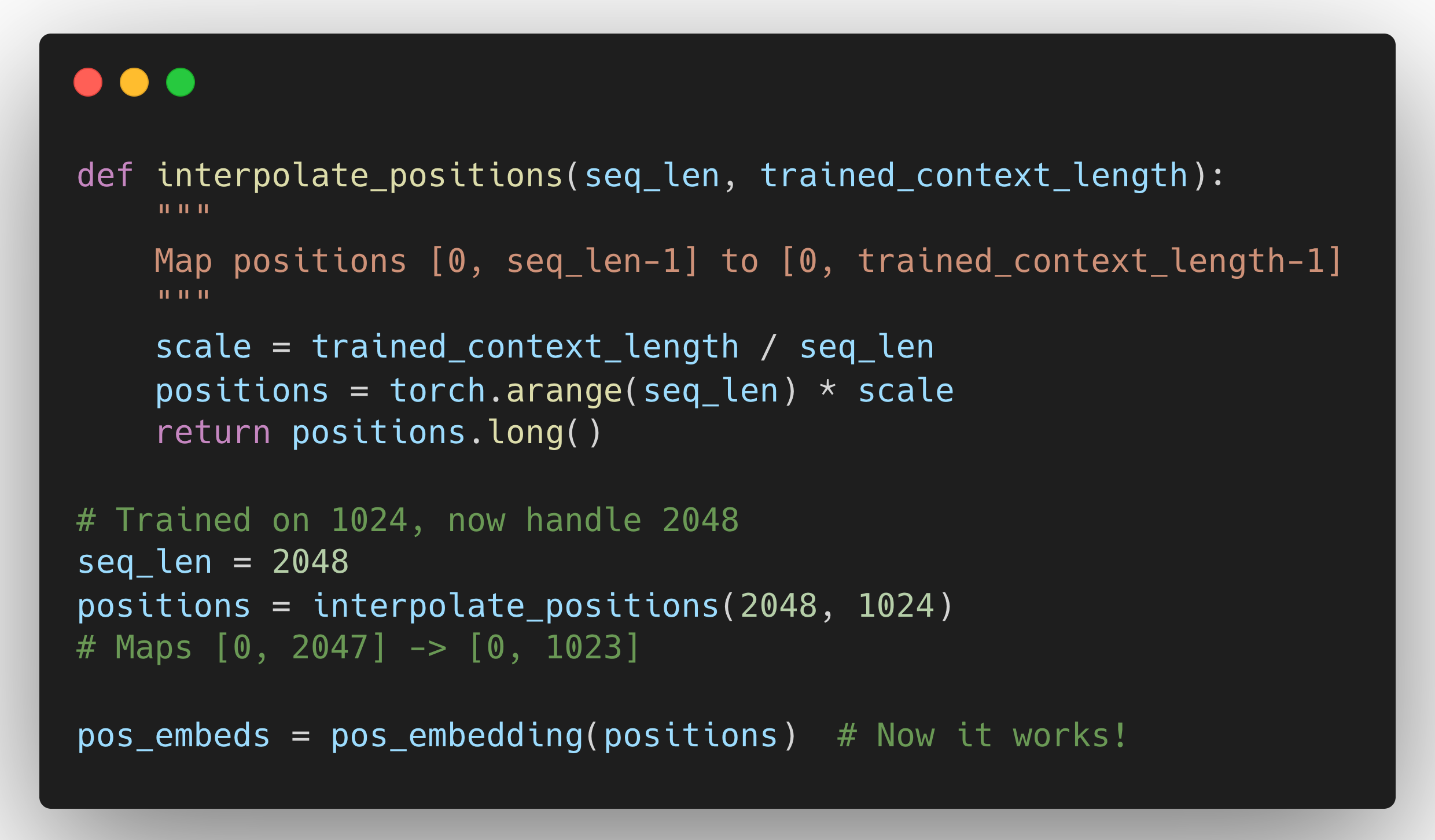
This is how many "extended context" models work. Meta's LLaMA 2 was extended from 4K to 32K using this. It's a common trick to "stretch" context without retraining from scratch (position interpolation / scaling), but it trades off positional resolution and can hurt retrieval of far-away details.
Downside: You're squeezing more tokens into the same positional space. Position 0 and position 1 used to be adjacent, now they might represent positions 0 and 2. The model has to adapt.
Method 2: RoPE (Rotary Position Embeddings)
Instead of learned positional embeddings, use a mathematical function that naturally extrapolates.
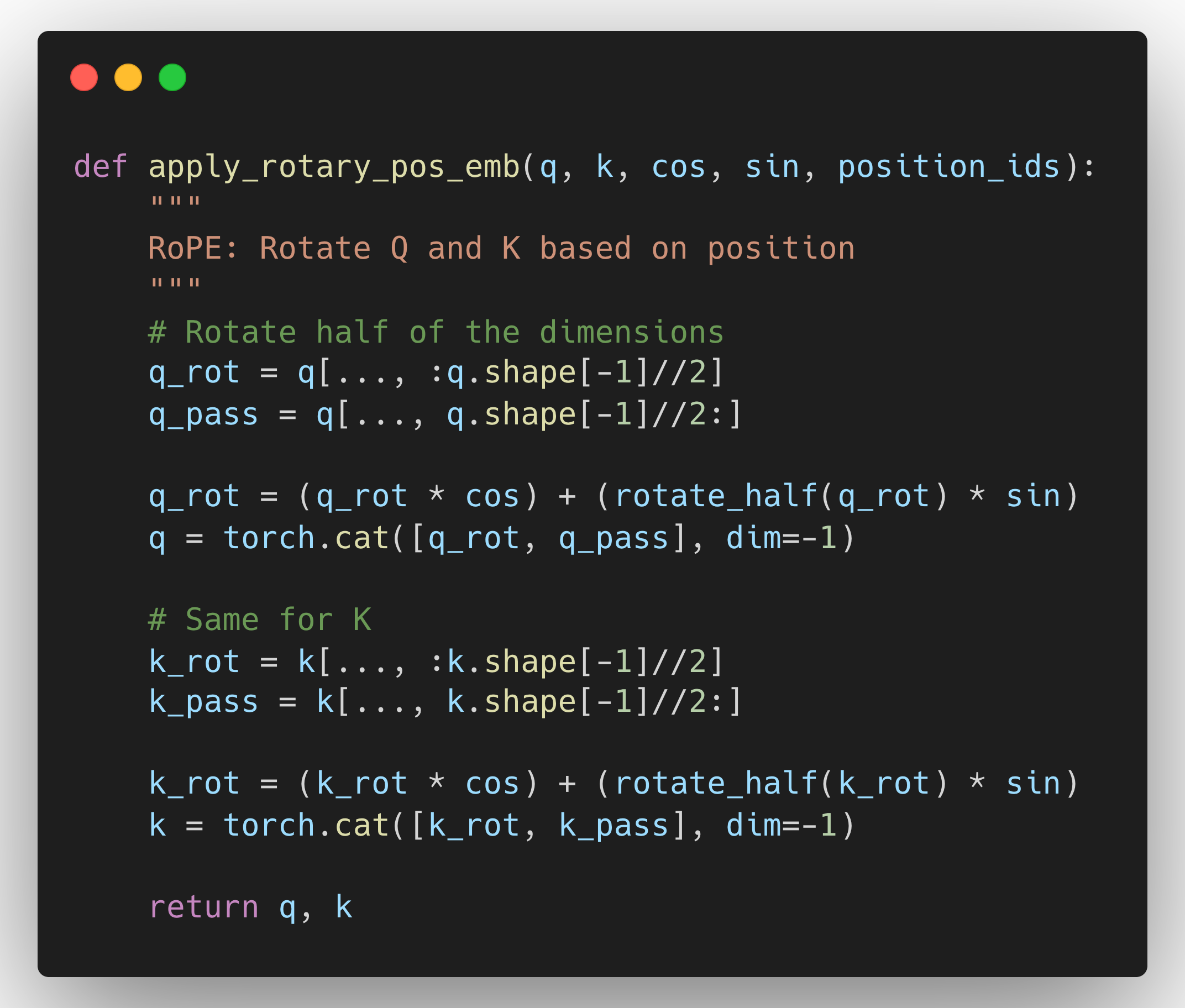
Why RoPE is better: It's a mathematical operation, not a lookup table. So it can extrapolate to positions it never saw during training.
Used in: LLaMA, Mistral, many modern models.
Still not perfect: Even RoPE degrades beyond ~2x the training length. You need techniques like YaRN (Yet another RoPE extensioN) to go further.
Method 3: Sparse Attention
Don't attend to ALL previous tokens. Use patterns like:
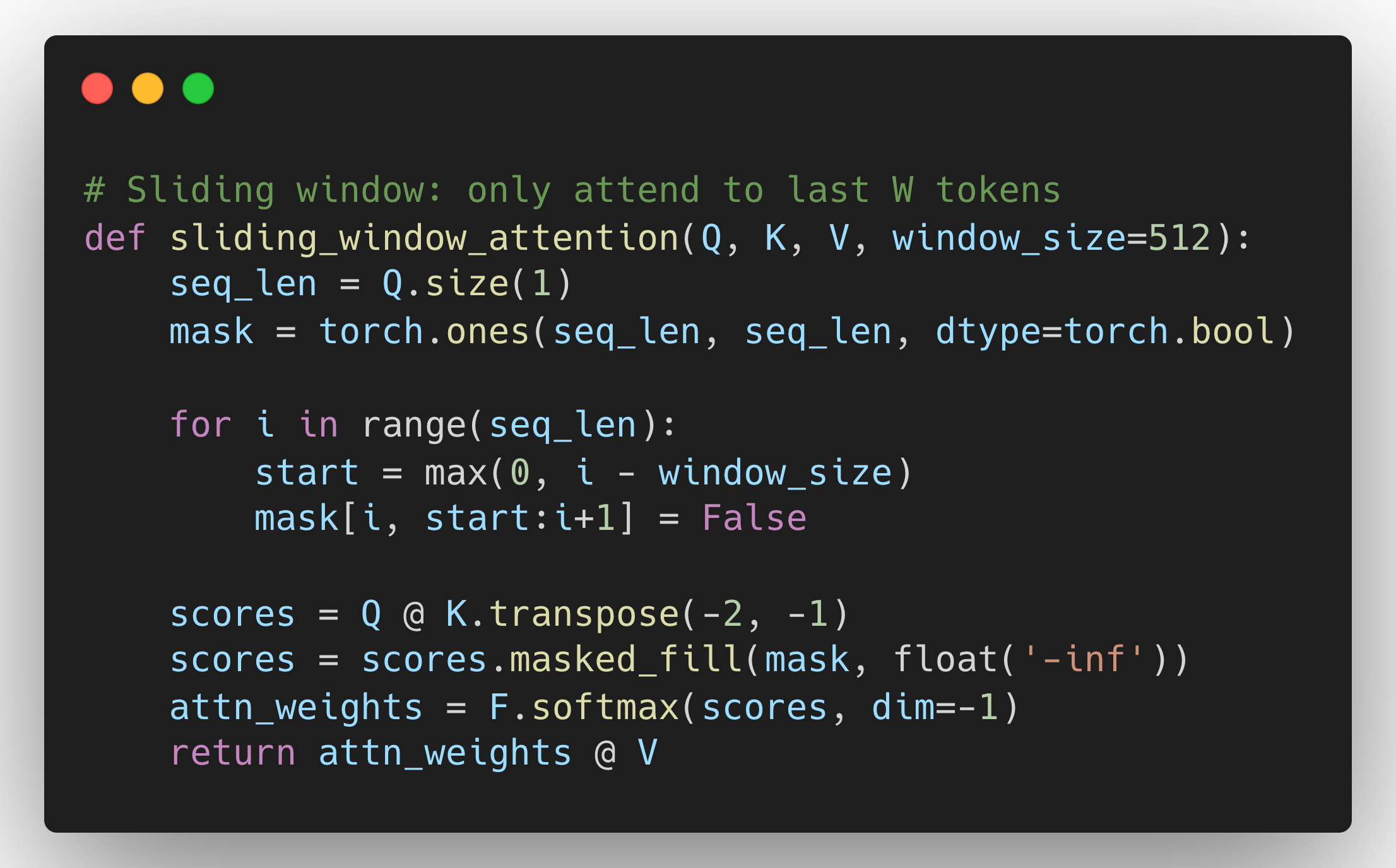
Longformer, BigBird use sparse patterns. Complexity drops from O(n²) to O(n×window).
Tradeoff: You can't attend to ALL previous context anymore. You might miss important info from 50K tokens ago.
Method 4: Continue Training on Longer Sequences
The most expensive but most reliable method.
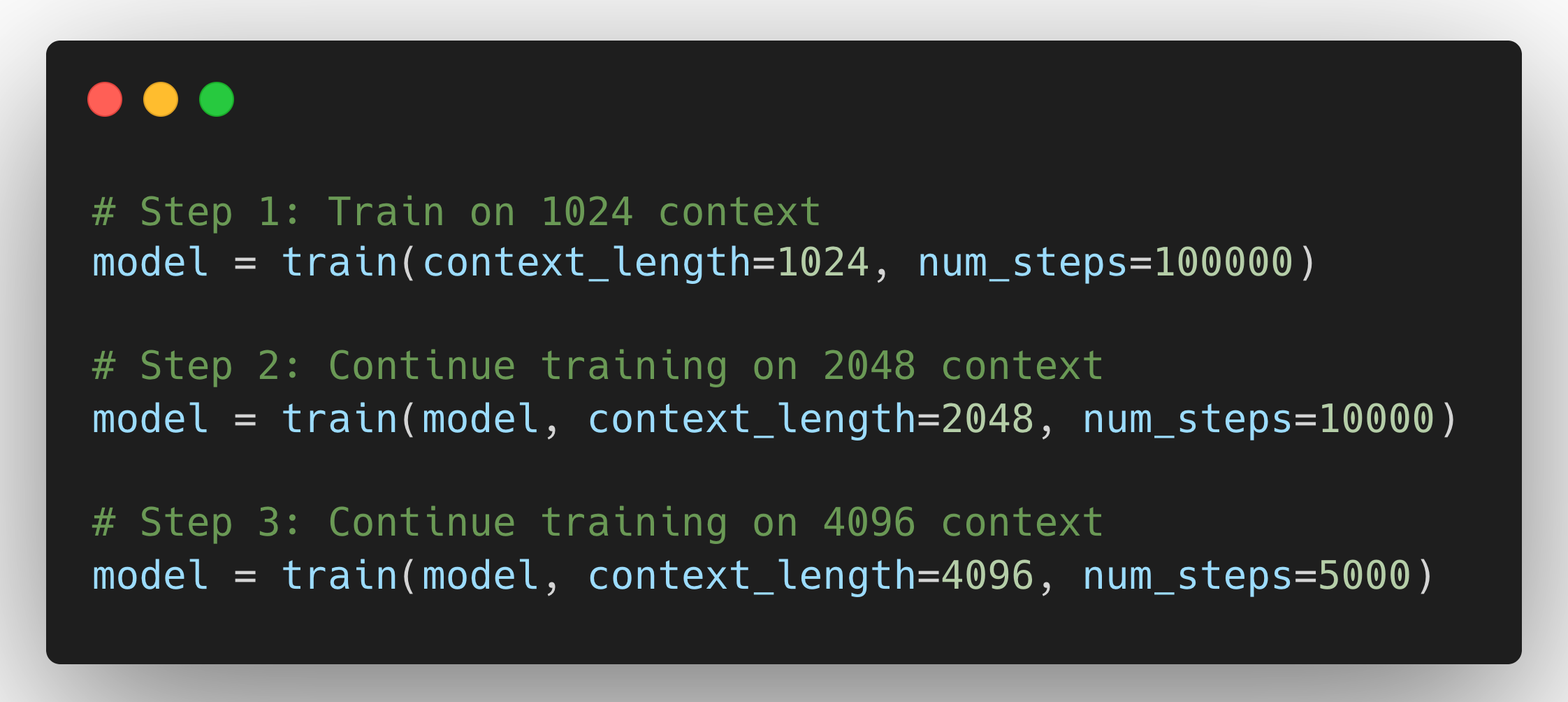
Why it works: The model actually learns the new positional patterns.
Cost: Expensive. Training on longer sequences is way more expensive (remember O(n²)).
What We've Learned So Far
Context length isn't just a marketing number you see in model release announcements. It's a fundamental architectural constraint that cascades through every part of the system:
At training time:
- Your positional embeddings define the hard upper limit
- You must allocate memory for n×n attention matrices
- Longer sequences = quadratically more compute and memory
At inference time:
- You can't exceed the trained context length without architectural modifications
- Extensions like positional interpolation or RoPE scaling can help, but they come with tradeoffs
- The model's ability to effectively use long context degrades as you push beyond its training length
The key insight: When a model card says "128K context," it means the architecture was specifically designed and trained to handle 128K tokens. Getting there required careful architectural choices (likely RoPE instead of absolute positional embeddings), extensive training runs with long sequences, and accepting significant computational costs.
But We're Only Halfway There
Understanding the architecture is just half the story. The other half is equally important: how do you actually serve these long-context models in production?
Because here's the reality check - even if your model can architecturally handle 128K tokens, deploying it at that context length comes with brutal tradeoffs:
- Memory walls: KV cache requirements that can consume hundreds of GBs per request
- Throughput collapse: Serving capacity that drops by 10-100x compared to shorter contexts
- Batching nightmares: Fitting multiple requests in memory becomes a puzzle
- Cost explosion: Infrastructure costs that make your CFO nervous
These aren't theoretical concerns. They're the day-to-day reality of running LLM inference at scale.
What's Next?
In Part 2: Context Length in Production, we'll shift from architecture to systems. We'll explore:
- Why KV cache management is your biggest bottleneck and how techniques like PagedAttention solve it
- Real memory calculations showing why a single 128K request can be more expensive than 64 short requests
- How production serving frameworks (vLLM, TensorRT-LLM) handle long context efficiently
- Batching strategies and why you can't just throw more GPUs at the problem
- Practical cost models and when you should (and shouldn't) use long context
The architectural understanding you have now will make the systems challenges much clearer.
"In the meantime, try this exercise: Take your favorite open-source model (LLaMA, Mistral, etc.) and calculate how much KV cache memory you'd need to serve 10 concurrent 64K context requests. The numbers might surprise you."
Until the next deep dive, keep experimenting and challenging the norms! 🚀
Happy Modeling!
References
- Extending Context Window of Large Language Models via Positional Interpolation
- RoFormer: Enhanced Transformer with Rotary Position Embedding
- Generating Long Sequences with Sparse Transformers
- Longformer: The Long-Document Transformer
- Big Bird: Transformers for Longer Sequences
- Language Models are Few-Shot Learners (GPT-3)
- Language Models are Unsupervised Multitask Learners (GPT-2)