Emerging Properties in Self-Supervised Vision Transformers: DINO Paper Summary

Introduction
Hi Everyone! Today, we'll dive into one of the most interesting self-supervised learning approaches I've come across: "Emerging Properties in Self-Supervised Vision Transformers". This exploration seeks to demystify DINO (Self-DIstillation with NO Labels), providing a comprehensive understanding of its mechanics, contributions, and distinctions.
Big Idea
The research paper "Emerging Properties in Self-Supervised Vision Transformers" introduces DINO (Self-DIstillation with NO Labels), an innovative approach to self-supervised learning.
DINO works with Vision Transformers (ViTs) and also convnets (like ResNet-50), though the paper focuses on ViTs to study emergent attention and segmentation behavior. It employs self-distillation, where a student model learns by aligning its outputs with a dynamically updated teacher model. This approach leads to the emergence of visual prototypes without the need for labeled data.
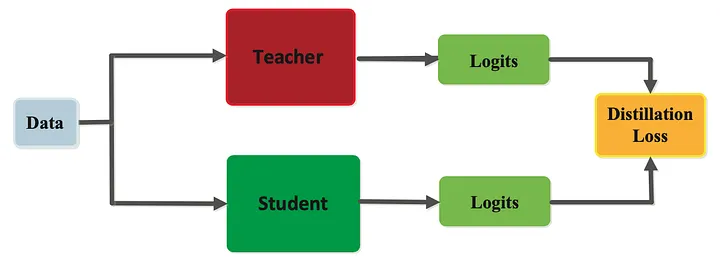
Knowledge Distillation
DINO framework is similar to a self-supervised learning approach, but it also shares similarities with Knowledge Distillation process as well. Let's try to understand the Knowledge Distillation process in brief before moving forward.
Knowledge distillation is a powerful technique aimed at transferring the knowledge from a larger, more complex model (referred to as the "teacher" network) to a smaller, simpler model (known as the "student" network). Let's delve into this process in detail.
In knowledge distillation, we consider two neural networks:
- Teacher network - gθt
- Student network - gθs
where, θt and θs represent the parameters of the teacher and student networks respectively.
Given an input image x, both networks generate probability distributions over K dimensions, symbolized by Pt and Ps for the teacher and student networks respectively.
The probability P is calculated by normalizing the output of the network g using the Softmax activation function. Mathematically, the student's output probability Ps(x) for each class i is computed as:
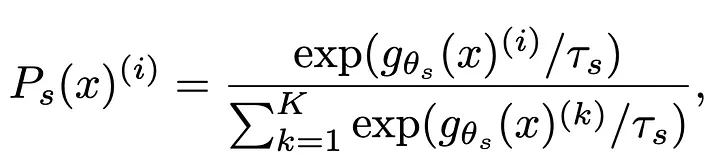
where τs is a positive temperature parameter that controls the sharpness of the output distribution. A similar formula is used to calculate Pt for the teacher network, with its own temperature parameter τt.
In simpler terms, knowledge distillation guides the Student to produce outputs similar to that of the Teacher by adjusting its parameters θs such that the cross-entropy between teacher and student distributions is minimized (which is closely related to KL divergence up to constants). This process allows the student network to learn from the rich representations encoded by the teacher, thereby improving its own performance even when trained on a smaller dataset or having a simpler architecture.
The Essence of Self-Supervision and Contrastive Learning
Collecting and labeling data can be expensive, and the costs can increase significantly for commercial applications. To address this, self-supervised learning can be employed to allow a model to initially learn the characteristics and details of the subject within images without relying on labeled data. Afterward, the model can be fine-tuned using a smaller set of labeled data.
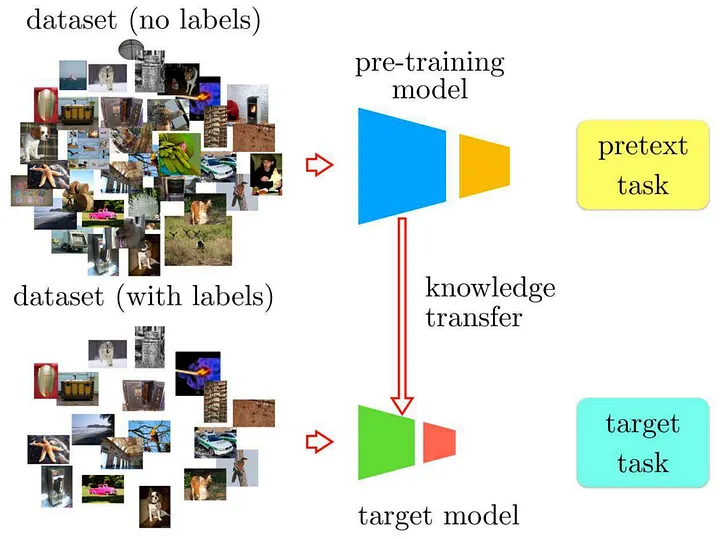
Self-supervised learning is a clever approach that allows models to learn without the need for labeled data. The model learns meaningful representations by solving pretext tasks designed from the data itself, such as predicting rotations, colorizing images, or in DINO's case, matching different views of the same image.
Self-Supervised Learning (SSL) with Knowledge Distillation: A Comparison
As we saw above, traditional knowledge distillation involves training a smaller student model to imitate the predictions of a larger pre-trained teacher model. However, DINO takes a distinctive twist on this concept.
So, what is the difference between Knowledge Distillation and SSL with DINO?
Let's try to answer this question.
Traditional Knowledge Distillation
- Teacher Model: A pre-trained, larger model, usually frozen during training.
- Student Model: A smaller model, trained via back-propagation to mimic the teacher's predictions.
- Objective: Transfer knowledge by matching the teacher's soft outputs (logits/probabilities).
- Model Diversity: Teacher and student can be different models, e.g., ResNet50 (Teacher) and SqueezeNet (Student).
- Loss Function: Typically uses cross-entropy between teacher and student distributions (closely related to KL divergence).
SSL with DINO (DIstillation of NOisy labels)
Training Approach
DINO introduces a unique approach to knowledge distillation:
- Multi-crop Strategy: DINO generates various distorted views (crops) from an image, including two global views and several lower-resolution local views, using different augmentations.
- Local-to-Global Learning: All crops are passed through the student model, but only global views are processed by the teacher model. This teaches the student to relate local image patches with the global context from the teacher.
- Cross-view Matching: The loss is computed across cross-view pairs — the teacher processes one global view, and the student's outputs on other views (both global and local) are matched to the teacher's distribution. This encourages consistency across different perspectives of the same image.
Model Architecture
In the standard DINO implementation using an EMA (Exponential Moving Average) teacher setup, teacher and student share the same architecture. The reason for this is that when we train the Student model, we take the Exponential Moving Average of its weights and update the Teacher model with that.
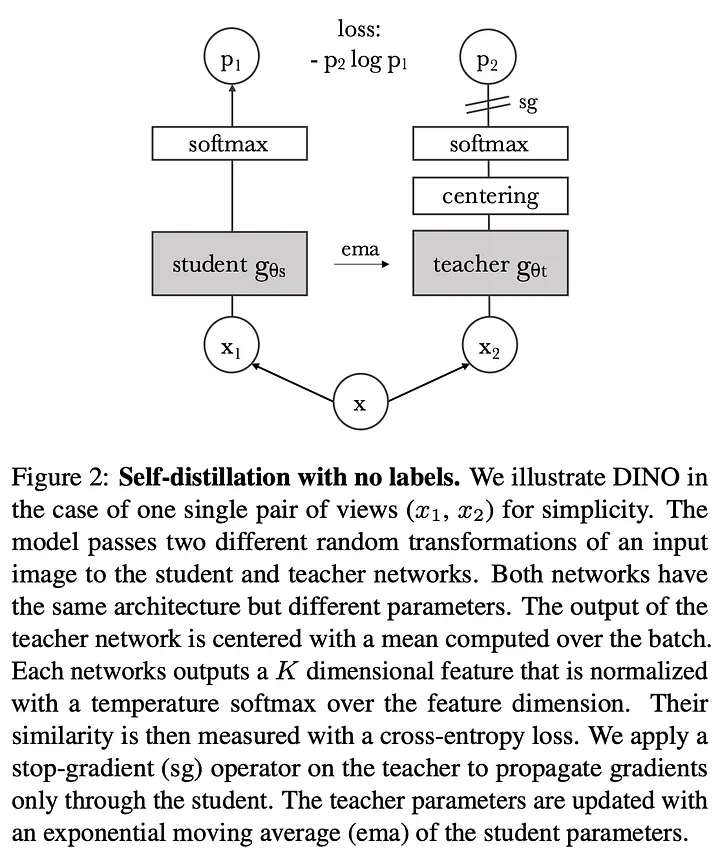
If the Teacher model's architecture were different or larger than that of the Student model, some layers would not match after performing the EMA weight update. These mismatched layers would retain their randomly initialized weights, which is not beneficial.
- Weight Updates: The Student model is trained using back-propagation, and its weights are used to update the Teacher model using Exponential Moving Average (EMA). The official implementation uses a momentum parameter that starts at 0.996 and increases to 1.0 following a cosine schedule.
- Dynamic Teacher: The teacher model is updated dynamically, preventing the student from overfitting to static representations. If the Teacher model weights were static (i.e., not updated), the Student might quickly overfit to the specific representations provided by that static Teacher. By having a dynamically updated teacher via EMA, the Student constantly adapts to slightly changing targets, promoting better generalization.
- Projection Head: DINO doesn't use a supervised label classifier. Instead, it uses a projection head (a 3-layer MLP with hidden dimension 2048, ending in a weight-normalized fully-connected layer) that maps features to K prototype dimensions. In the official code, K defaults to 65,536, representing the DINO head output dimensionality — these are prototype logits, not semantic classes.
- Loss Calculation: The cross-entropy loss is computed between the teacher's and student's probability distributions (obtained by applying Softmax with temperature to the prototype logits).
Comparative Analysis
So, what distinguishes Knowledge Distillation from SSL with DINO?
- Model Dynamics: In traditional distillation, only the student model is trained, while in DINO, both models are updated (student via backprop, teacher via EMA).
- Architectural Flexibility: Traditional knowledge distillation allows for different model architectures, whereas DINO's standard EMA setup requires identical architectures to ensure effective weight updates.
- Learning Objective: DINO uses cross-entropy loss to match the student's output distribution to the teacher's output distribution across different views of the same image. Unlike contrastive learning methods that use negative samples and contrastive losses, DINO does not require negative pairs or a memory queue.
- Temperature Settings: DINO uses different temperatures for teacher and student — the teacher uses a sharper softmax (low temperature), often with a warmup schedule (the paper mentions warming from 0.04 → 0.07 early in training), while the student uses a higher temperature, encouraging exploration.
Now that we understand the basics of DINO, let's look at some of the important parts of it.
How DINO Works Without Contrastive Learning
Important Note: DINO does NOT use contrastive learning or negative sampling. Instead, it uses a simpler and more elegant approach based on matching distributions across views.
The Core Idea
For each image in a batch, DINO creates multiple augmented views (crops). The student network processes all views, while the teacher network only processes the global (larger) views. The student learns to match the teacher's output distribution for the same image across different view pairs.
Understanding the Loss Function
Let's understand this with help of an example:
Suppose we have an image. DINO creates:
- 2 global crops (large views)
- Several local crops (smaller patches)
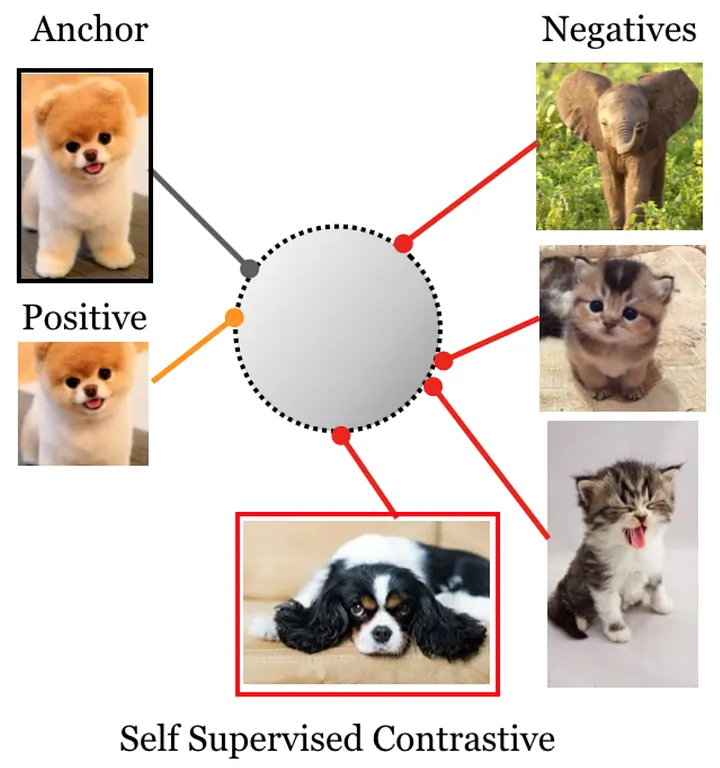
Here's what happens:
- The student processes ALL crops (global + local), producing a K-dimensional output for each (where K = 65,536 prototype dimensions by default)
- The teacher processes ONLY the 2 global crops, producing K-dimensional outputs
- For each global teacher view, we compute cross-entropy loss with student outputs from OTHER views
- This creates cross-view pairs: if the teacher sees global view 1, the student's outputs on global view 2 and all local views are matched to it
Here's what makes DINO different from contrastive learning:
- No negative pairs: DINO doesn't explicitly push apart representations from different images in the batch
- No contrastive loss: There's no InfoNCE loss or similar contrastive objective
- Batch-wise softmax: The softmax is computed over the prototype dimensions (K), not over the batch
- Cross-entropy objective: The loss is simply the cross-entropy between teacher and student distributions
The Loss Function
The loss for DINO is averaged over all cross-view pairs:
L = -(1/n) Σ Pt(x) * log(Ps(x'))
Where:
- Pt(x) is the teacher's output probability distribution for a global view of image x (after softmax with low temperature and centering)
- Ps(x') is the student's output probability distribution for a different view x' of the same image (after Softmax with higher temperature)
- The sum is over all valid cross-view pairs
This is a standard cross-entropy loss, but applied in a self-supervised manner where the teacher's outputs serve as soft targets for the student across different views of the same image.
Why Cross-Entropy Works Here
DINO's cross-entropy loss encourages the student to produce similar output distributions to the teacher for different views of the same image. The teacher's output acts as a pseudo-label or soft target, representing a consistent "prototype assignment" for that image.
The key insight is that by matching distributions across views WITHOUT negative samples, DINO learns meaningful representations through consistency alone, combined with techniques to prevent collapse.
Exponential Moving Averages (EMA)
EMA is instrumental in stabilizing training by mitigating abrupt fluctuations in the weights. The teacher's parameters undergo a continual update as follows:
W_teacher = λ W_teacher + (1-λ) W_student
where λ is a momentum parameter. In the official DINO code, this defaults to 0.996 and is increased to 1.0 during training following a cosine schedule. This ensures the teacher evolves smoothly as a running average of past student states.
Avoiding Model Collapse
Centering and Sharpening
DINO introduces complementary techniques — centering and sharpening — to prevent collapse to trivial solutions:
- Centering: Applied to the teacher's output before the softmax to prevent one dimension from dominating. DINO maintains a running average (center) of the teacher's output across the batch and subtracts it:
c ← mc + (1-m) * mean_batch(teacher_output)
teacher_centered = teacher_output - c
where m is a momentum for the center update; values around 0.9 work well based on their ablation studies. This prevents the model from collapsing to always predicting the same prototype.
- Sharpening: Applied by using a low temperature in the softmax function for the teacher's outputs, making the distribution more peaked and confident. The paper uses a warmup schedule that starts at a lower temperature and increases it early in training (e.g., from 0.04 → 0.07):
Pt(x) = exp(teacher_output / τ_teacher) / Σ exp(teacher_output / τ_teacher)
The student uses a higher temperature, allowing for softer, more exploratory predictions.
The paper explicitly explains that centering and sharpening have complementary effects: centering prevents collapse by ensuring uniform prototype usage across the batch, while sharpening encourages confident, discriminative predictions.
Vocabulary of Prototypes
Additionally, DINO learns a dynamic vocabulary of visual prototypes, which are activation patterns representing diverse visual concepts. These emerge naturally in the K output dimensions of the projection head (65,536 by default), allowing the network to discover and represent a rich set of visual patterns without supervision.
DINO Model Training Steps
Now that we have covered everything, let's summarize the steps for DINO model training:
- Initialization: Begin by initializing both the Teacher and Student models with the same architecture (e.g., ViT-S/16 or ResNet-50). The teacher can be initialized as a copy of the student or with the same random weights.
- Data Augmentation: Load a batch of images. For each image in the batch, create multiple augmented views: typically 2 global crops (higher resolution, covering a larger portion of the image) and several local crops (lower resolution, covering smaller patches).
- Model Forward Pass:
- Pass ALL crops (global + local) through the Student model
- Pass ONLY the 2 global crops through the Teacher model
- Each model generates K-dimensional prototype logits (K = 65,536 by default)
- Loss Calculation: Calculate the cross-entropy loss across cross-view pairs:
- Apply centering to teacher outputs (subtract running center)
- Apply softmax with low temperature to teacher outputs → Pt (sharp distribution; often uses warmup schedule)
- Apply softmax with higher temperature to student outputs → Ps (softer distribution)
- For each global teacher view, compute cross-entropy with student outputs from OTHER views
- Average the loss over all cross-view pairs
- Back-propagation and Weight Update:
- Back-propagate through the Student model to update its weights using standard gradient descent
- Update the Teacher model's weights using Exponential Moving Average (EMA) of the Student model's weights: W_teacher ← λ W_teacher + (1-λ) W_student
- Update the running center for centering
- No gradients flow through the teacher (teacher is updated only via EMA)
Key Findings
- Firstly, Self-supervised ViT features contain explicit information about the semantic segmentation of an image, which does not emerge as clearly with supervised ViTs, nor with convnets.

- Second, these features are also excellent k-NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT. Our study also underlines the importance of momentum encoder, multi-crop training, and the use of small patches with ViTs.

- Emergence of Visual Prototypes: DINO's self-supervised learning leads to the spontaneous emergence of class-level visual prototypes in the deeper layers of the network. These prototypes capture intricate visual patterns across diverse categories.
- Superior Performance: The models trained using DINO outperform several existing self-supervised learning methods, setting new benchmarks in multiple visual recognition tasks.

- Effective Use of Vision Transformers (ViTs): The research demonstrates that ViTs can be effectively used in a self-supervised setting, utilizing their ability to capture long-range dependencies in the data.
- Robustness to Augmentations: DINO is shown to be robust to various input augmentations, showcasing its adaptability and ability to learn meaningful representations.
- No Need for Labels: The DINO approach effectively leverages self-distillation without requiring any labeled data, marking a significant advancement in unsupervised learning techniques.
- Simplified Training Process: DINO simplifies the training process by eliminating the need for a fixed dictionary or a memory bank, which are commonly used in contrastive learning methods.
Key Takeaway
DINO showcases a paradigm shift in self-supervised learning by demonstrating that a student model can learn intricate visual representations without labeled data by emulating a dynamically updated teacher model built from past student iterations via EMA.
The approach stands out for its elegance and simplicity: unlike contrastive learning methods that require carefully managing negative samples and large batch sizes or memory queues, DINO achieves excellent results using only cross-entropy loss between different views of the same image, combined with centering and sharpening techniques to prevent collapse.
The emergence of semantic segmentation in DINO's attention maps without any explicit supervision for segmentation demonstrates that self-supervised learning with Vision Transformers can discover visual structure that goes beyond what supervised training reveals.
This makes DINO both conceptually simpler and practically effective, opening new directions for self-supervised learning in computer vision.
Until the next deep dive, keep experimenting and challenging the norms! 🚀
Happy Modeling!